HueShift: Breathing Life into Every Frame
HueShift transforms grayscale videos into vibrant color using two different deep learning approaches: Diffusion Models and Generative Adversarial Networks (GANs). Our goal was to develop and compare these methods, with a special focus on ensuring temporal consistency and realistic coloration across frames.
Our Dual Approach
1. Diffusion-Based Approach
Our diffusion model works by iteratively adding and removing noise:
- LAB Color Space Processing - Separates luminance ("L" channel) from color ("A" and "B" channels), allowing us to denoise only color components
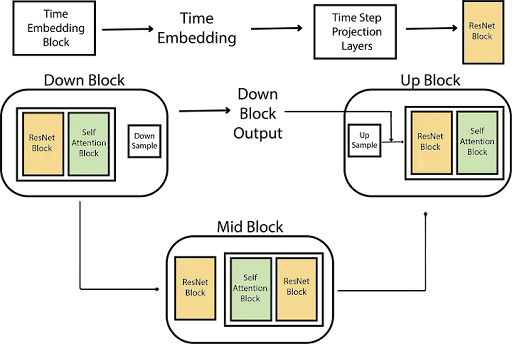
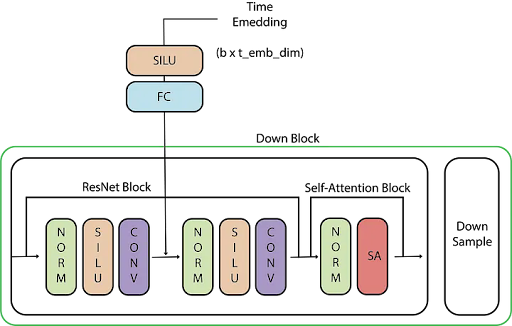
- U-Net Architecture - A 3-channel LAB input with noised AB channels passes through encoder, bottleneck, and decoder with skip connections
- Noise Scheduling - Carefully calibrated variance schedule controls the noise addition/removal process
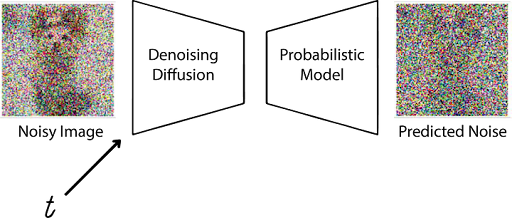
- Forward Process - Gaussian noise is added to color channels in increasing amounts over T timesteps
- Reverse Process - The model learns to predict and remove noise iteratively, conditioned on grayscale input
- Resolution Enhancement - Bicubic interpolation upscales low-resolution outputs while preserving original grayscale details
- Neural Deflickering - Flawed atlas approach identifies and corrects temporal inconsistencies between frames
Our model was trained on vast.ai GPUs using keyframes from the UCF101 dataset. The diffusion process allows for high-quality colorization by gradually learning to reverse the noise addition process, guided by the grayscale input.

2. GAN-Based Approach
Our GAN implementation uses saliency maps to guide colorization:
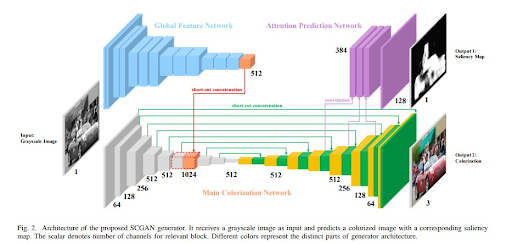
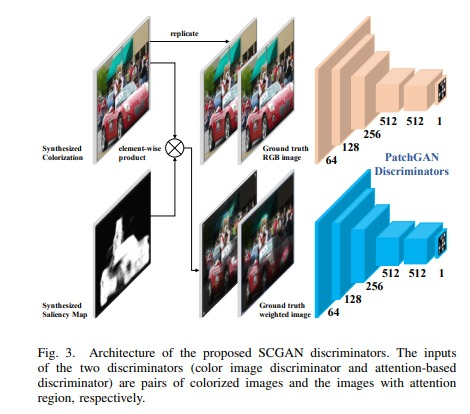
- SCGAN-Based Generator - Modified with channel reduction at deeper layers for improved training stability
- Saliency Detection - Pyramid Feature Attention Network identifies visually important regions
- 70×70 PatchGAN Discriminators:
- Standard discriminator - Enforces global color realism
- Attention discriminator - Focuses on salient regions for detail refinement
- Loss Functions - Balanced combination of adversarial, L1, and perceptual losses
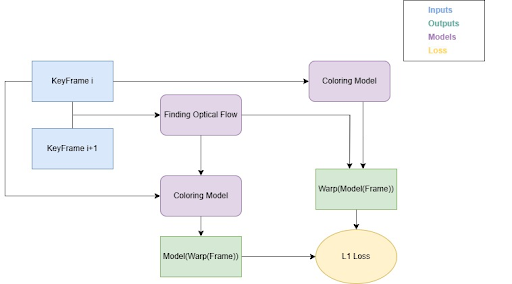
- Optical Flow - FastFlowNet tracks motion between frames to maintain color consistency
- Adaptive Color Propagation - Warps colors from keyframes to subsequent frames based on motion vectors
We deviated from the original SCGAN design by reducing channel counts as network depth increased, improving efficiency and reducing overfitting. The dual-discriminator setup enhances both global color realism and local detail accuracy.
Sample Results
Diffusion Model
GAN Model
Technical Challenges
Achieving Temporal Consistency
Our videos were deflickered through a two-stage neural approach:
Atlas Generation Stage
Video frames were processed by mapping each pixel's (x,y,t) coordinates to a consistent 2D atlas space using a 6-layer MLP network without positional encoding. Colors were reconstructed using an 8-layer MLP with positional encoding at 10 frequency bands. This mapping was optimized through a combination of RGB reconstruction loss (weight 5000), optical flow consistency loss (weight 500), rigidity loss (weight 1.0), and gradient preservation loss (weight 1000) for 10,000 iterations at 768×432 resolution.
Neural Filtering Stage
The second stage applied a UNet-based neural filter with 32 initial features followed by a TransformNet with ConvLSTM for temporal consistency. This refined the atlas-reconstructed frames to preserve details while maintaining temporal consistency. The final output, stored in the "final" directory at the original resolution, shows the video with flickering successfully removed while preserving natural motion and details.
References & Resources
Denoising Diffusion Probabilistic Models
The foundation for our diffusion-based approach
Blind Video Deflickering by Neural Filtering with a Flawed Atlas
Used for ensuring temporal consistency in our diffusion approach
SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network
The basis for our GAN-based approach